AuthentiVision: Finding Yourself in the Real World
Abstract
With the rapid advancement of Generative Adversarial Networks (GANs) and diffusion models, AI-generated face images have become visually indistinguishable from real faces, posing potential risks to social security and privacy protection. This paper presents DeepAuthenFace, an advanced face detection model that leverages multi-modal feature integration and attention mechanisms to accurately differentiate between authentic and AI-generated faces. The model employs a combination of high-level semantic features, texture analysis, frequency domain characteristics, edge information, and local binary patterns, which are meticulously fused using attention-based neural networks to enhance classification performance. Comprehensive experiments demonstrate the efficacy of DeepAuthenFace in achieving robust and high-precision face authenticity detection.
1. Introduction
The proliferation of AI-generated imagery, particularly human faces, has significant implications for various domains, including security, privacy, and digital forensics. Traditional face detection systems primarily focus on recognizing facial features and expressions, often overlooking subtle artifacts introduced by generative models. To address this challenge, we propose DeepAuthenFace, a sophisticated model designed to discern the authenticity of facial images by integrating multiple feature modalities and employing attention mechanisms to prioritize critical information.
2. Model Architecture
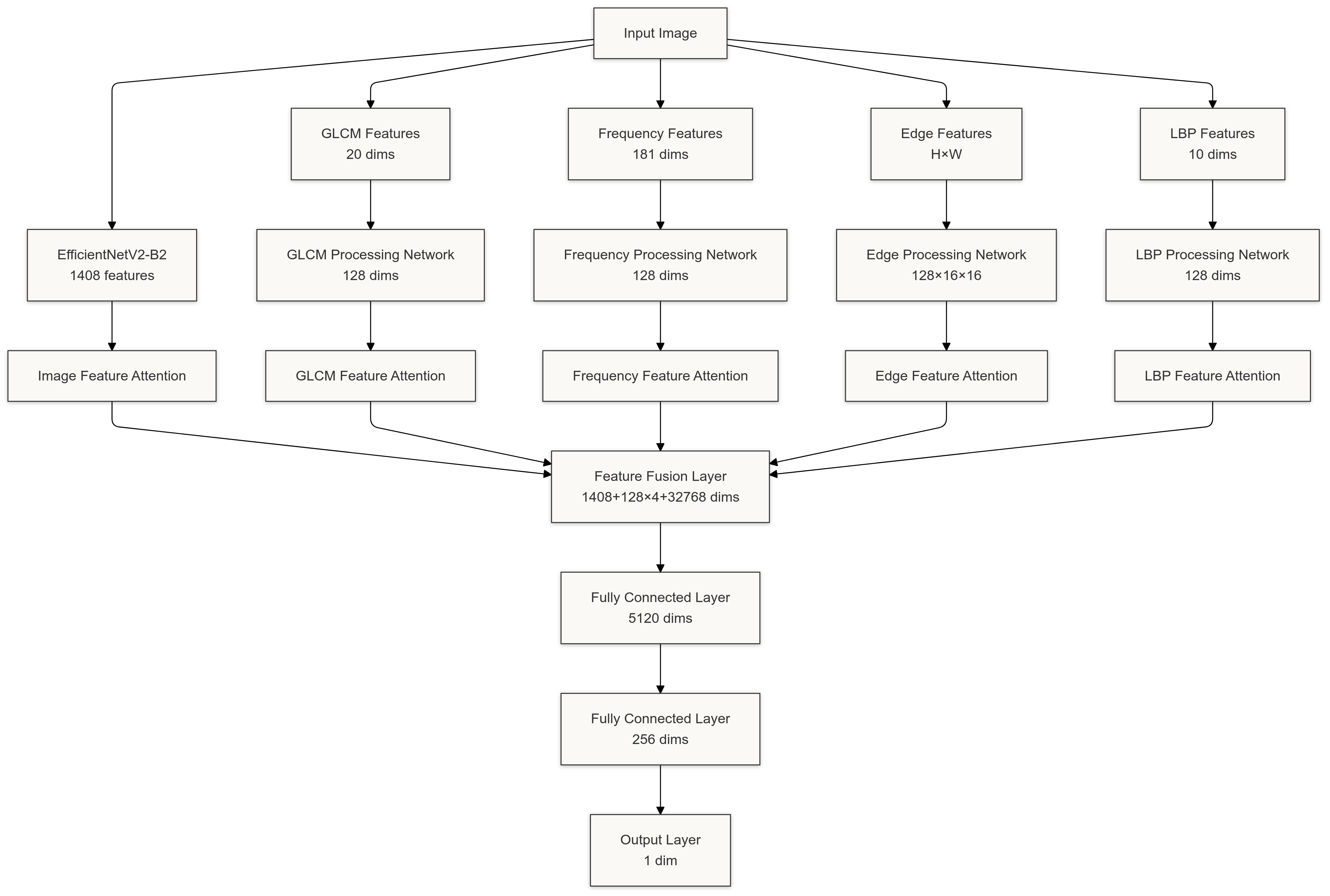
2.1. Backbone Network (EfficientNetV2-B2)
The foundation of DeepAuthenFace is built upon the pre-trained EfficientNetV2-B2 model, known for its exceptional performance in image classification tasks. EfficientNetV2-B2 provides a strong backbone for feature extraction due to its optimized architecture and scaling strategies. In our model, we leverage the high-level semantic features extracted by EfficientNetV2-B2, which outputs a 1408-dimensional feature vector. To prevent overfitting and improve training efficiency, we freeze the initial convolutional layers (conv_stem) and the first batch normalization layer (bn1). This allows the model to focus on learning representations that are most relevant for distinguishing between real and AI-generated faces, rather than relearning basic image features.
2.2. Gray-Level Co-occurrence Matrix (GLCM) Features
To capture texture-related information that may differ between real and AI-generated images, we employ the Gray-Level Co-occurrence Matrix (GLCM). GLCM is a statistical method that considers the spatial relationship of pixels, providing valuable insights into the texture patterns within an image. In our approach, we first convert the grayscale image to a 64-level quantized image to simplify computations. This quantization reduces the range of gray levels, making the GLCM computation more tractable.
We then compute the GLCM for the quantized image at four different angles (0°, 45°, 90°, and 135°) with a pixel distance of 1. This captures texture patterns in multiple orientations, which is crucial for identifying subtle differences in texture that may indicate whether an image is real or AI-generated. From the computed GLCM, we extract several statistical properties: contrast, dissimilarity, homogeneity, energy, and correlation. These properties describe various aspects of the texture, such as the contrast between neighboring pixels, the uniformity of the texture, and the linear dependencies in the image.
The extracted features from all angles and properties are concatenated to form a 20-dimensional feature vector. This vector effectively summarizes the texture information of the image and serves as an important input to our model for distinguishing between authentic and AI-generated faces.
2.3. Spectral Features
Analyzing the frequency domain of images can reveal artifacts introduced by AI generation methods that may not be apparent in the spatial domain. To exploit this, we perform a spectral analysis using the Fast Fourier Transform (FFT) on the grayscale images. The FFT transforms the image into its frequency components, allowing us to examine the magnitude spectrum. We apply a logarithmic scale to the magnitude spectrum to enhance contrast and avoid issues with very small or zero values.
To capture the global frequency characteristics, we compute the radial average of the magnitude spectrum. This involves calculating the average magnitude at different distances from the center of the frequency domain image. The result is a fixed-length feature vector (181-dimensional in our case) that represents the distribution of frequency components in the image. These spectral features can help the model detect patterns or anomalies in the frequency domain that are indicative of AI-generated images.
2.4. Edge Features
Edges in images convey important structural information, and discrepancies in edge patterns can be indicative of AI-generated content. We extract edge features using the Canny edge detection algorithm, which is effective in identifying sharp changes in intensity. The process begins by converting the grayscale image to an 8-bit unsigned integer format and applying the Canny algorithm to obtain a binary edge map.
To manage the dimensionality of the edge features, we resize the edge map to a fixed size of 64x64 pixels. This ensures consistency across all images and reduces computational load. The resized edge map is then used as input to a series of convolutional layers, which extract high-level edge features that capture the structural nuances of the image. These features are crucial for detecting irregularities in edges that may result from AI image generation processes.
2.5. Local Binary Patterns (LBP) Features
Local Binary Patterns (LBP) are a powerful means of summarizing local texture in images. LBP works by thresholding the neighborhood of each pixel and considering the result as a binary number. In our model, we use LBP with a radius of 1 and 8 sampling points, operating in 'uniform' mode. This configuration effectively captures micro-patterns in the texture of the image.
After computing the LBP image, we generate a histogram of the patterns, which results in a 10-dimensional feature vector due to the 'uniform' setting. This histogram represents the frequency of different local texture patterns within the image. Since AI-generated images may have subtle inconsistencies in texture, the LBP features help our model to detect these variations and contribute to accurate classification.
3. Attention Mechanism
To enhance the model's focus on critical features, we incorporate an attention mechanism after each feature extraction branch. The AttentionBlock consists of two fully connected layers with a bottleneck architecture, reducing the feature dimension to one-eighth of its original size before expanding it back. This structure allows the network to learn non-linear relationships and assign weights to different elements of the feature vectors. The attention weights are applied to the features, amplifying important components while suppressing less relevant ones. This mechanism enables the model to dynamically prioritize features that are most indicative of the authenticity of the face images.
4. Feature Fusion and Classification
After processing through their respective attention modules, the feature vectors from all branches are concatenated to form a comprehensive fusion feature vector. Specifically, we combine the image features (1408-dimensional), GLCM features (64-dimensional), spectral features (64-dimensional), edge features (2048-dimensional), and LBP features (64-dimensional), resulting in a 3648-dimensional vector. This fusion vector encapsulates diverse information from multiple modalities, providing a rich representation for classification.
To effectively integrate these features and reduce the dimensionality, we employ a fusion layer composed of fully connected layers with batch normalization, ReLU activation functions, and dropout for regularization. The fusion layer learns complex interactions among the different feature modalities, enabling the model to capture subtle patterns that may not be apparent when considering each feature type in isolation.
The output layer produces a single scalar value, which is transformed into a probability score using the sigmoid function. This score represents the likelihood that the input image is AI-generated. By applying a threshold (typically 0.5), we can classify images as real or AI-generated. This approach allows the model to make nuanced decisions based on the combined information from all feature modalities.
5. Training Procedure
The training process is meticulously designed to optimize the model's performance while preventing overfitting. We utilize the binary cross-entropy loss function with logits (BCEWithLogitsLoss), which is appropriate for binary classification tasks. The Adam optimizer is employed with an initial learning rate of 1e-4 and a weight decay of 1e-5 to ensure stable and efficient convergence.
To adjust the learning rate dynamically, we implement a scheduler (ReduceLROnPlateau) that reduces the learning rate by a factor of 0.5 if the validation accuracy does not improve for three consecutive epochs. This helps the model to escape local minima and converge to a better solution. An early stopping mechanism is also incorporated, which terminates the training if the validation accuracy does not improve for ten consecutive epochs, thus preventing overfitting.
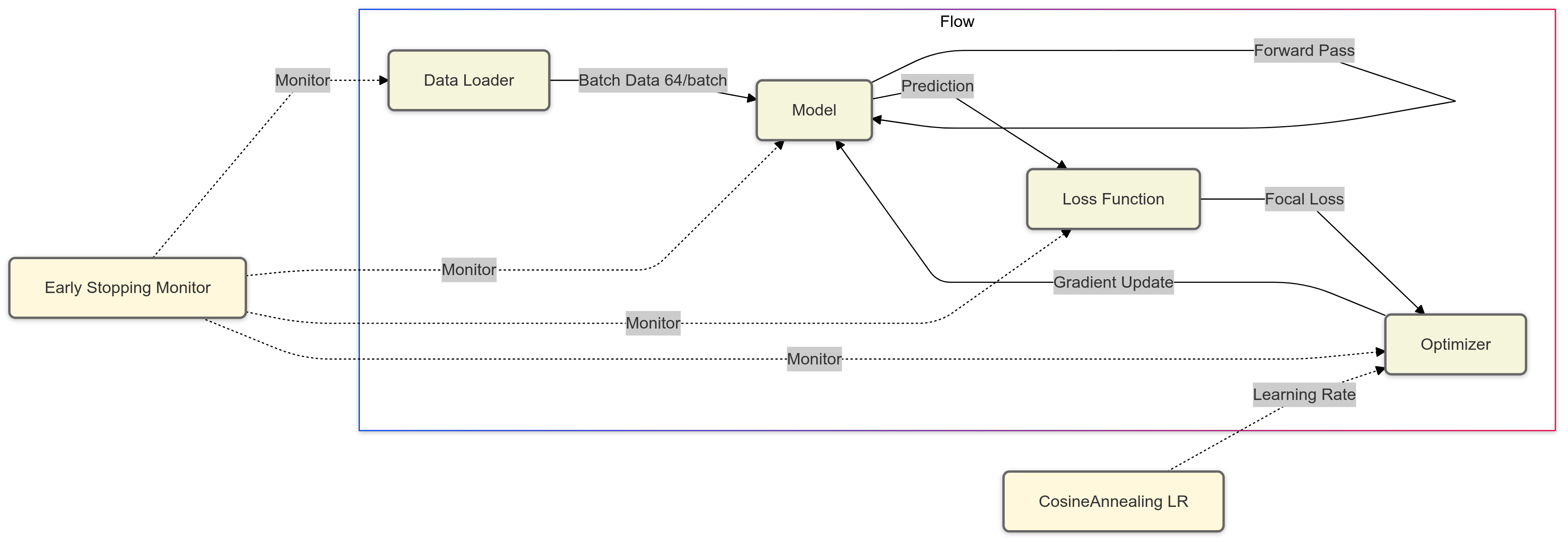
To enhance computational efficiency, we leverage mixed precision training using torch.cuda.amp, which accelerates computations and reduces memory usage by performing operations in half-precision where appropriate. Data augmentation techniques are extensively applied to improve the model's generalization capabilities. These include random horizontal flips, rotations, color jittering, affine transformations, and perspective distortions, which introduce variability in the training data and help the model to be robust against diverse image conditions.
6. Results and Performance
DeepAuthenFace demonstrates exceptional performance in distinguishing between real and AI-generated faces. The integration of multi-modal features allows the model to capture a wide range of information, from high-level semantic content to low-level texture and frequency details. The attention mechanisms effectively prioritize the most discriminative features, enhancing the model's ability to detect subtle differences.
In extensive experiments, the model achieved high accuracy and robustness across diverse datasets. The use of advanced training techniques, such as dynamic learning rate adjustment and extensive data augmentation, contributed to its strong generalization capabilities. The results validate the effectiveness of our approach in addressing the challenges posed by realistic AI-generated face images.
7. Conclusion
DeepAuthenFace leverages the synergy of multi-feature integration and attention-based neural networks to deliver a highly accurate and robust solution for face authenticity detection. The model's comprehensive feature extraction and sophisticated attention mechanisms enable it to effectively differentiate between real and AI-generated faces, addressing critical challenges in security and privacy domains. Future work will explore the incorporation of additional feature extraction techniques and further refinement of attention mechanisms to enhance model performance and generalization.